1 前言
Deep Reinforcement Learning可以说是当前深度学习领域最前沿的研究方向,研究的目标即让机器人具备决策及运动控制能力。话说人类创造的机器灵活性还远远低于某些低等生物,比如蜜蜂。。DRL就是要干这个事,而是关键是使用神经网络来进行决策控制。
因此,考虑了一下,决定推出DRL前沿系列,第一时间推送了解到的DRL前沿,主要是介绍最新的研究成果,不讲解具体方法(考虑到博主本人也没办法那么快搞懂)。也因此,本文对于完全不了解这个领域,或者对这个领域感兴趣的童鞋都适合阅读。
下面进入正题。
2 Benchmarking Deep Reinforcement Learning for Continuous Control
文章出处:
时间:2016年4月25日 开源软件地址:这篇文章不是什么创新算法的文章,但却是极其重要的一篇文章,看到文章的第一眼就能看出来。这篇文章针对DRL在连续控制领域的问题弄了一个Benchmark,而且,关键是作者把程序开源了,按照作者的原话就是
To encourage adoption by other researchers!
在这篇文章中,或者说这个开源软件包中,作者将主流及前沿的几个用于连续控制领域的算法都用python复现了,然后将算法应用在31种不同难度的连续控制问题上。
那么一共分了四类任务: 1)简单任务:让倒立摆保持平衡之类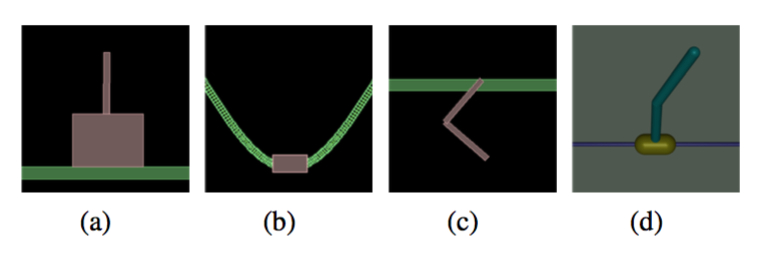
2)运动任务:让里面的虚拟生物往前跑,越快越好!
3)不完全可观察任务:即虚拟生物只能得到有限的感知信息,比如只知道每个关节的位置但不知道速度
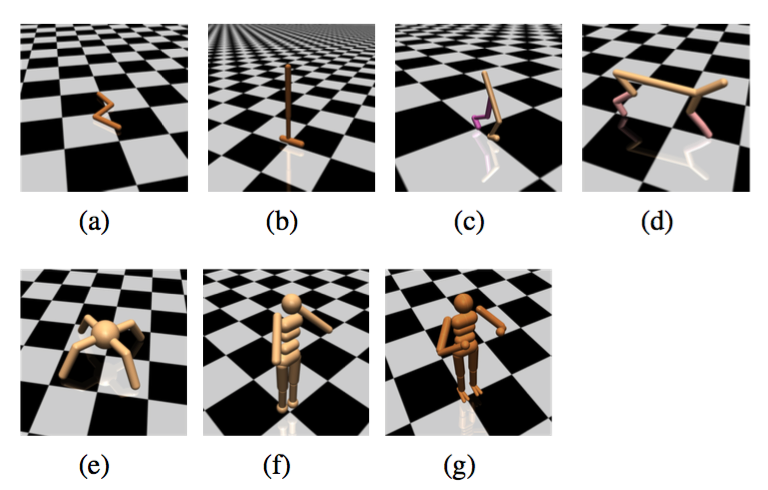
4)层次化任务:包含顶层决策+底层控制。比如下面的让虚拟蚂蚁找食物或者让虚拟蛇走迷宫。这种难度就很大了。

那么有了同样的测试环境,就可以对不同的算法进行对比。
对比出来的结果就是:
- TNPG和TRPO这两个方法(UC Berkerley的Schulman提出,现在属于OpenAI)最好,DDPG(DeepMind的David Silver团队提出的)次之。
- 层次任务目前没有一个算法能够完成,催生新的algorithm。
然后文章并没有对DeepMind的A3C算法进行测试,而这个是目前按DeepMind的文章最好的算法.
3 小结
UC Berkerley这次的开源相信对于学术界来说具有重要影响,很多研究者将受益于他们对于复现算法的公开。之后的研究恐怕也会在此Benchmark上进行测试。